Overview¶
This notebook is designed to provide a broad overview of Hail’s functionality, with emphasis on the functionality to manipulate and query a genetic dataset. We walk through a genome-wide SNP association test, and demonstrate the need to control for confounding caused by population stratification.
Each notebook starts the same: we import the hail package and create
a HailContext. This
object is the entry point for most Hail functionality.
In [1]:
from hail import *
hc = HailContext()
Running on Apache Spark version 2.0.2
SparkUI available at http://10.56.135.40:4040
Welcome to
__ __ <>__
/ /_/ /__ __/ /
/ __ / _ `/ / /
/_/ /_/\_,_/_/_/ version 0.1-5a67787
If the above cell ran without error, we’re ready to go!
Before using Hail, we import some standard Python libraries for use throughout the notebook.
In [2]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from collections import Counter
from math import log, isnan
from pprint import pprint
%matplotlib inline
Installing and importing seaborn is optional; it just makes the plots prettier.
In [3]:
# optional
import seaborn
Check for tutorial data or download if necessary¶
This cell downloads the necessary data from Google Storage if it isn’t found in the current working directory.
In [4]:
import os
if os.path.isdir('data/1kg.vds') and os.path.isfile('data/1kg_annotations.txt'):
print('All files are present and accounted for!')
else:
import sys
sys.stderr.write('Downloading data (~50M) from Google Storage...\n')
import urllib
import tarfile
urllib.urlretrieve('https://storage.googleapis.com/hail-1kg/tutorial_data.tar',
'tutorial_data.tar')
sys.stderr.write('Download finished!\n')
sys.stderr.write('Extracting...\n')
tarfile.open('tutorial_data.tar').extractall()
if not (os.path.isdir('data/1kg.vds') and os.path.isfile('data/1kg_annotations.txt')):
raise RuntimeError('Something went wrong!')
else:
sys.stderr.write('Done!\n')
All files are present and accounted for!
Loading data from disk¶
Hail has its own internal data representation, called a Variant Dataset (VDS). This is both an on-disk file format and a Python object. See the overview for a complete story. Here, we read a VDS from disk.
This dataset was created by downsampling a public 1000 genomes VCF to about 50 MB.
In [5]:
vds = hc.read('data/1kg.vds')
Getting to know our data¶
It’s important to have easy ways to slice, dice, query, and summarize a dataset. Some of these methods are demonstrated below.
The summarize method is useful for providing a broad overview of the data contained in a dataset.
In [6]:
vds.summarize().report()
Samples: 1000
Variants: 10961
Call Rate: 0.983163
Contigs: ['X', '12', '8', '19', '4', '15', '11', '9', '22', '13', '16', '5', '10', '21', '6', '1', '17', '14', '20', '2', '18', '7', '3']
Multiallelics: 0
SNPs: 10961
MNPs: 0
Insertions: 0
Deletions: 0
Complex Alleles: 0
Star Alleles: 0
Max Alleles: 2
The query_variants method is the first time we’ll see the Hail expression language. The expression language allows for a variety of incredibly expressive queries and computations, but is probably the most complex part of Hail. See the pair of tutorials on the expression language to learn more!
Here, we can use query_variants to pull out 5 variants to see what
they look like.
In [7]:
vds.query_variants('variants.take(5)')
Out[7]:
[Variant(contig=1, start=904165, ref=G, alts=[AltAllele(ref=G, alt=A)]),
Variant(contig=1, start=909917, ref=G, alts=[AltAllele(ref=G, alt=A)]),
Variant(contig=1, start=986963, ref=C, alts=[AltAllele(ref=C, alt=T)]),
Variant(contig=1, start=1563691, ref=T, alts=[AltAllele(ref=T, alt=G)]),
Variant(contig=1, start=1707740, ref=T, alts=[AltAllele(ref=T, alt=G)])]
There are often several ways to do something in Hail. Here are two ways to peek at the first few sample IDs:
In [8]:
vds.query_samples('samples.take(5)')
Out[8]:
[u'HG00096', u'HG00097', u'HG00099', u'HG00100', u'HG00101']
In [9]:
vds.sample_ids[:5]
Out[9]:
[u'HG00096', u'HG00097', u'HG00099', u'HG00100', u'HG00101']
There’s a similar interface for looking at the genotypes in a dataset. We use query_genotypes to look at the first few genotype calls.
In [10]:
vds.query_genotypes('gs.take(5)')
Out[10]:
[Genotype(GT=0, AD=[4, 0], DP=4, GQ=12, PL=[0, 12, 194]),
Genotype(GT=1, AD=[4, 3], DP=7, GQ=85, PL=[85, 0, 109]),
Genotype(GT=0, AD=[1, 0], DP=1, GQ=3, PL=[0, 3, 42]),
Genotype(GT=0, AD=[14, 0], DP=14, GQ=42, PL=[0, 42, 533]),
Genotype(GT=0, AD=[12, 0], DP=12, GQ=36, PL=[0, 36, 420])]
Integrate sample annotations¶
Hail treats variant and sample annotations as first-class citizens. Annotations are usually a critical part of any genetic study. Sample annotations are where you’ll store information about sample phenotypes, ancestry, sex, and covariates. Variant annotations can be used to store information like gene membership and functional impact for use in QC or analysis.
In this tutorial, we demonstrate how to take a text file and use it to annotate the samples in a VDS.
iPython supports various cell “magics”. The %%sh magic is one which
interprets the cell with bash, rather than Python. We can use this to
look at the first few lines of our annotation file. This file contains
the sample ID, the population and “super-population” designations, the
sample sex, and two simulated phenotypes (one binary, one discrete).
In [11]:
%%sh
head data/1kg_annotations.txt | column -t
sh: 1: column: not found
head: write error: Broken pipe
This file can be imported into Hail with HailContext.import_table. This method produces a KeyTable object. Think of this as a Pandas or R dataframe that isn’t limited by the memory on your machine – behind the scenes, it’s distributed with Spark.
In [12]:
table = hc.import_table('data/1kg_annotations.txt', impute=True)\
.key_by('Sample')
2018-10-18 01:26:28 Hail: INFO: Reading table to impute column types
2018-10-18 01:26:28 Hail: INFO: Finished type imputation
Loading column `Sample' as type String (imputed)
Loading column `Population' as type String (imputed)
Loading column `SuperPopulation' as type String (imputed)
Loading column `isFemale' as type Boolean (imputed)
Loading column `PurpleHair' as type Boolean (imputed)
Loading column `CaffeineConsumption' as type Int (imputed)
A good way to peek at the structure of a KeyTable is to look at its
schema.
In [13]:
print(table.schema)
Struct{Sample:String,Population:String,SuperPopulation:String,isFemale:Boolean,PurpleHair:Boolean,CaffeineConsumption:Int}
The Python pprint method makes illegible printouts pretty:
In [14]:
pprint(table.schema)
Struct{
Sample: String,
Population: String,
SuperPopulation: String,
isFemale: Boolean,
PurpleHair: Boolean,
CaffeineConsumption: Int
}
Although we used the %%sh magic to look at the first lines of the
table, there’s a better way. We can convert the table to a Spark
DataFrame
and use its .show() method:
In [15]:
table.to_dataframe().show(10)
+-------+----------+---------------+--------+----------+-------------------+
| Sample|Population|SuperPopulation|isFemale|PurpleHair|CaffeineConsumption|
+-------+----------+---------------+--------+----------+-------------------+
|NA19784| MXL| AMR| false| false| 8|
|NA19102| YRI| AFR| true| false| 6|
|HG00141| GBR| EUR| false| false| 6|
|HG01890| ACB| AFR| false| false| 8|
|HG00263| GBR| EUR| true| true| 6|
|NA20908| GIH| SAS| true| true| 9|
|HG04075| STU| SAS| true| false| 9|
|NA18982| JPT| EAS| false| false| 5|
|NA12873| CEU| EUR| true| false| 6|
|HG02677| GWD| AFR| true| true| 5|
+-------+----------+---------------+--------+----------+-------------------+
only showing top 10 rows
Now we’ll use this table to add sample annotations to our dataset. First, we’ll print the schema of the sample annotations already there:
In [16]:
pprint(vds.sample_schema)
Empty
We use the annotate_samples_table method to join the table with the VDS.
In [17]:
vds = vds.annotate_samples_table(table, root='sa')
In [18]:
pprint(vds.sample_schema)
Struct{
Population: String,
SuperPopulation: String,
isFemale: Boolean,
PurpleHair: Boolean,
CaffeineConsumption: Int
}
Query functions and the Hail Expression Language¶
We start by looking at some statistics of the information in our table. The query method uses the expression language to aggregate over the rows of the table.
counter is an aggregation function that counts the number of
occurrences of each unique element. We can use this to pull out the
population distribution.
In [19]:
pprint(table.query('SuperPopulation.counter()'))
{u'AFR': 1018L, u'AMR': 535L, u'EAS': 617L, u'EUR': 669L, u'SAS': 661L}
stats is an aggregation function that produces some useful
statistics about numeric collections. We can use this to see the
distribution of the CaffeineConsumption phenotype.
In [20]:
pprint(table.query('CaffeineConsumption.stats()'))
{u'max': 10.0,
u'mean': 6.219714285714286,
u'min': 3.0,
u'nNotMissing': 3500L,
u'stdev': 1.9387801550964772,
u'sum': 21769.0}
However, these metrics aren’t perfectly representative of the samples in our dataset. Here’s why:
In [21]:
table.count()
Out[21]:
3500L
In [22]:
vds.num_samples
Out[22]:
1000
Since there are fewer samples in our dataset than in the full thousand genomes cohort, we need to look at annotations on the dataset. We can do this with query_samples.
In [23]:
vds.query_samples('samples.map(s => sa.SuperPopulation).counter()')
Out[23]:
{u'AFR': 101L, u'AMR': 285L, u'EAS': 308L, u'EUR': 298L, u'SAS': 8L}
In [24]:
pprint(vds.query_samples('samples.map(s => sa.CaffeineConsumption).stats()'))
{u'max': 10.0,
u'mean': 6.783000000000003,
u'min': 3.0,
u'nNotMissing': 1000L,
u'stdev': 1.624780292839619,
u'sum': 6783.000000000003}
The functionality demonstrated in the last few cells isn’t anything
especially new: it’s certainly not difficult to ask these questions with
Pandas or R dataframes, or even Unix tools like awk. But Hail can
use the same interfaces and query language to analyze collections that
are much larger, like the set of variants.
Here we calculate the counts of each of the 12 possible unique SNPs (4 choices for the reference base * 3 choices for the alternate base). To do this, we need to map the variants to their alternate allele, filter to SNPs, and count by unique ref/alt pair:
In [25]:
snp_counts = vds.query_variants('variants.map(v => v.altAllele()).filter(aa => aa.isSNP()).counter()')
pprint(Counter(snp_counts).most_common())
[(AltAllele(ref=C, alt=T), 2436L),
(AltAllele(ref=G, alt=A), 2387L),
(AltAllele(ref=A, alt=G), 1944L),
(AltAllele(ref=T, alt=C), 1879L),
(AltAllele(ref=C, alt=A), 496L),
(AltAllele(ref=G, alt=T), 480L),
(AltAllele(ref=T, alt=G), 468L),
(AltAllele(ref=A, alt=C), 454L),
(AltAllele(ref=C, alt=G), 150L),
(AltAllele(ref=G, alt=C), 112L),
(AltAllele(ref=T, alt=A), 79L),
(AltAllele(ref=A, alt=T), 76L)]
It’s nice to see that we can actually uncover something biological from this small dataset: we see that these frequencies come in pairs. C/T and G/A are actually the same mutation, just viewed from from opposite strands. Likewise, T/A and A/T are the same mutation on opposite strands. There’s a 30x difference between the frequency of C/T and A/T SNPs. Why?
The same Python, R, and Unix tools could do this work as well, but we’re starting to hit a wall - the latest gnomAD release publishes about 250 million variants, and that won’t fit in memory on a single computer.
What about genotypes? Hail can query the collection of all genotypes in the dataset, and this is getting large even for our tiny dataset. Our 1,000 samples and 10,000 variants produce 10 million unique genotypes. The gnomAD dataset has about 5 trillion unique genotypes.
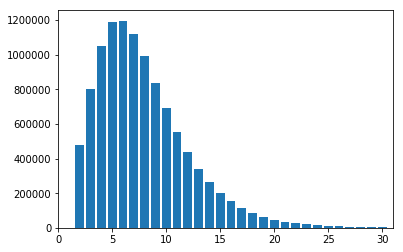
Here we will use the hist aggregator to produce and plot a histogram
of DP values for genotypes in our thousand genomes dataset.
In [26]:
dp_hist = vds.query_genotypes('gs.map(g => g.dp).hist(0, 30, 30)')
plt.xlim(0, 31)
plt.bar(dp_hist.binEdges[1:], dp_hist.binFrequencies)
plt.show()
Quality Control¶
QC is where analysts spend most of their time with sequencing datasets. QC is an iterative process, and is different for every project: there is no “push-button” solution for QC. Each time the Broad collects a new group of samples, it finds new batch effects. However, by practicing open science and discussing the QC process and decisions with others, we can establish a set of best practices as a community.
QC is entirely based on the ability to understand the properties of a dataset. Hail attempts to make this easier by providing the sample_qc method, which produces a set of useful metrics as sample annotations.
In [27]:
pprint(vds.sample_schema)
Struct{
Population: String,
SuperPopulation: String,
isFemale: Boolean,
PurpleHair: Boolean,
CaffeineConsumption: Int
}
In [28]:
vds = vds.sample_qc()
In [29]:
pprint(vds.sample_schema)
Struct{
Population: String,
SuperPopulation: String,
isFemale: Boolean,
PurpleHair: Boolean,
CaffeineConsumption: Int,
qc: Struct{
callRate: Double,
nCalled: Int,
nNotCalled: Int,
nHomRef: Int,
nHet: Int,
nHomVar: Int,
nSNP: Int,
nInsertion: Int,
nDeletion: Int,
nSingleton: Int,
nTransition: Int,
nTransversion: Int,
dpMean: Double,
dpStDev: Double,
gqMean: Double,
gqStDev: Double,
nNonRef: Int,
rTiTv: Double,
rHetHomVar: Double,
rInsertionDeletion: Double
}
}
Interoperability is a big part of Hail. We can pull out these new metrics to a Pandas dataframe with one line of code:
In [30]:
df = vds.samples_table().to_pandas()
In [31]:
df.head()
Out[31]:
| s | sa.Population | sa.SuperPopulation | sa.isFemale | sa.PurpleHair | sa.CaffeineConsumption | sa.qc.callRate | sa.qc.nCalled | sa.qc.nNotCalled | sa.qc.nHomRef | ... | sa.qc.nTransition | sa.qc.nTransversion | sa.qc.dpMean | sa.qc.dpStDev | sa.qc.gqMean | sa.qc.gqStDev | sa.qc.nNonRef | sa.qc.rTiTv | sa.qc.rHetHomVar | sa.qc.rInsertionDeletion | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | HG00096 | GBR | EUR | False | False | 6 | 0.979017 | 10731 | 230 | 6321 | ... | 5233 | 1190 | 4.566828 | 2.343927 | 22.506570 | 22.531111 | 4410 | 4.397479 | 1.190760 | None |
| 1 | HG00097 | GBR | EUR | True | True | 6 | 0.993705 | 10892 | 69 | 6152 | ... | 5279 | 1251 | 9.440750 | 3.653101 | 42.334833 | 28.494689 | 4740 | 4.219824 | 1.648045 | None |
| 2 | HG00099 | GBR | EUR | True | False | 6 | 0.988687 | 10837 | 124 | 6113 | ... | 5377 | 1229 | 8.240004 | 3.720313 | 37.523761 | 28.130359 | 4724 | 4.375102 | 1.510096 | None |
| 3 | HG00100 | GBR | EUR | True | False | 6 | 0.999909 | 10960 | 1 | 6088 | ... | 5400 | 1238 | 12.756478 | 3.912233 | 52.740967 | 27.669909 | 4872 | 4.361874 | 1.758777 | None |
| 4 | HG00101 | GBR | EUR | False | True | 8 | 0.995347 | 10910 | 51 | 6229 | ... | 5358 | 1212 | 6.573118 | 2.887462 | 30.568286 | 25.611360 | 4681 | 4.420792 | 1.478031 | None |
5 rows × 26 columns
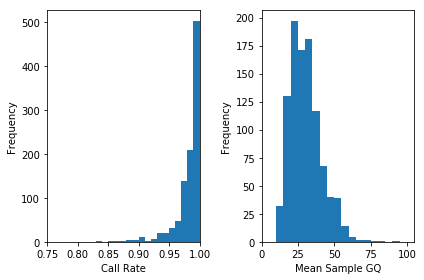
Plotting the QC metrics is a good place to start.
In [32]:
plt.clf()
plt.subplot(1, 2, 1)
plt.hist(df["sa.qc.callRate"], bins=np.arange(.75, 1.01, .01))
plt.xlabel("Call Rate")
plt.ylabel("Frequency")
plt.xlim(.75, 1)
plt.subplot(1, 2, 2)
plt.hist(df["sa.qc.gqMean"], bins = np.arange(0, 105, 5))
plt.xlabel("Mean Sample GQ")
plt.ylabel("Frequency")
plt.xlim(0, 105)
plt.tight_layout()
plt.show()
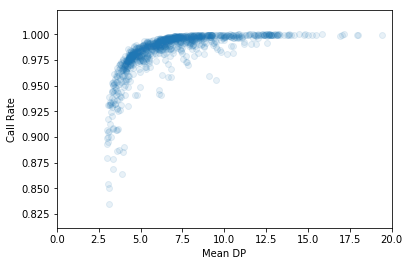
Often, these metrics are correlated.
In [33]:
plt.scatter(df["sa.qc.dpMean"], df["sa.qc.callRate"],
alpha=0.1)
plt.xlabel('Mean DP')
plt.ylabel('Call Rate')
plt.xlim(0, 20)
plt.show()
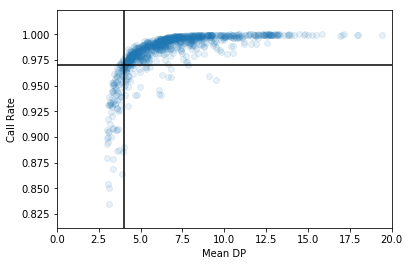
Removing outliers from the dataset will generally improve association results. We can draw lines on the above plot to indicate outlier cuts. We’ll want to remove all samples that fall in the bottom left quadrant.
In [34]:
plt.scatter(df["sa.qc.dpMean"], df["sa.qc.callRate"],
alpha=0.1)
plt.xlabel('Mean DP')
plt.ylabel('Call Rate')
plt.xlim(0, 20)
plt.axhline(0.97, c='k')
plt.axvline(4, c='k')
plt.show()
It’s easy to filter when we’ve got the cutoff values decided:
In [35]:
vds = vds.filter_samples_expr('sa.qc.dpMean >= 4 && sa.qc.callRate >= 0.97')
print('After filter, %d/1000 samples remain.' % vds.num_samples)
After filter, 843/1000 samples remain.
Next is genotype QC. To start, we’ll print the post-sample-QC call rate. It’s actually gone up since the initial summary - dropping low-quality samples disproportionally removed missing genotypes.
In [36]:
call_rate = vds.query_genotypes('gs.fraction(g => g.isCalled)')
print('pre QC call rate is %.3f' % call_rate)
pre QC call rate is 0.991
It’s a good idea to filter out genotypes where the reads aren’t where they should be: if we find a genotype called homozygous reference with >10% alternate reads, a genotype called homozygous alternate with >10% reference reads, or a genotype called heterozygote without a ref / alt balance near 1:1, it is likely to be an error.
In [37]:
filter_condition_ab = '''let ab = g.ad[1] / g.ad.sum() in
((g.isHomRef && ab <= 0.1) ||
(g.isHet && ab >= 0.25 && ab <= 0.75) ||
(g.isHomVar && ab >= 0.9))'''
vds = vds.filter_genotypes(filter_condition_ab)
In [38]:
post_qc_call_rate = vds.query_genotypes('gs.fraction(g => g.isCalled)')
print('post QC call rate is %.3f' % post_qc_call_rate)
post QC call rate is 0.955
Variant QC is a bit more of the same: we can use the variant_qc method to produce a variety of useful statistics, plot them, and filter.
In [39]:
pprint(vds.variant_schema)
Struct{
rsid: String,
qual: Double,
filters: Set[String],
pass: Boolean,
info: Struct{
AC: Array[Int],
AF: Array[Double],
AN: Int,
BaseQRankSum: Double,
ClippingRankSum: Double,
DP: Int,
DS: Boolean,
FS: Double,
HaplotypeScore: Double,
InbreedingCoeff: Double,
MLEAC: Array[Int],
MLEAF: Array[Double],
MQ: Double,
MQ0: Int,
MQRankSum: Double,
QD: Double,
ReadPosRankSum: Double,
set: String
}
}
The cache is used to optimize some of the downstream operations.
In [40]:
vds = vds.variant_qc().cache()
In [41]:
pprint(vds.variant_schema)
Struct{
rsid: String,
qual: Double,
filters: Set[String],
pass: Boolean,
info: Struct{
AC: Array[Int],
AF: Array[Double],
AN: Int,
BaseQRankSum: Double,
ClippingRankSum: Double,
DP: Int,
DS: Boolean,
FS: Double,
HaplotypeScore: Double,
InbreedingCoeff: Double,
MLEAC: Array[Int],
MLEAF: Array[Double],
MQ: Double,
MQ0: Int,
MQRankSum: Double,
QD: Double,
ReadPosRankSum: Double,
set: String
},
qc: Struct{
callRate: Double,
AC: Int,
AF: Double,
nCalled: Int,
nNotCalled: Int,
nHomRef: Int,
nHet: Int,
nHomVar: Int,
dpMean: Double,
dpStDev: Double,
gqMean: Double,
gqStDev: Double,
nNonRef: Int,
rHeterozygosity: Double,
rHetHomVar: Double,
rExpectedHetFrequency: Double,
pHWE: Double
}
}
In [42]:
variant_df = vds.variants_table().to_pandas()
plt.clf()
plt.subplot(2, 2, 1)
variantgq_means = variant_df["va.qc.gqMean"]
plt.hist(variantgq_means, bins = np.arange(0, 84, 2))
plt.xlabel("Variant Mean GQ")
plt.ylabel("Frequency")
plt.xlim(0, 80)
plt.subplot(2, 2, 2)
variant_mleaf = variant_df["va.qc.AF"]
plt.hist(variant_mleaf, bins = np.arange(0, 1.05, .025))
plt.xlabel("Minor Allele Frequency")
plt.ylabel("Frequency")
plt.xlim(0, 1)
plt.subplot(2, 2, 3)
plt.hist(variant_df['va.qc.callRate'], bins = np.arange(0, 1.05, .01))
plt.xlabel("Variant Call Rate")
plt.ylabel("Frequency")
plt.xlim(.5, 1)
plt.subplot(2, 2, 4)
plt.hist(variant_df['va.qc.pHWE'], bins = np.arange(0, 1.05, .025))
plt.xlabel("Hardy-Weinberg Equilibrium p-value")
plt.ylabel("Frequency")
plt.xlim(0, 1)
plt.tight_layout()
plt.show()
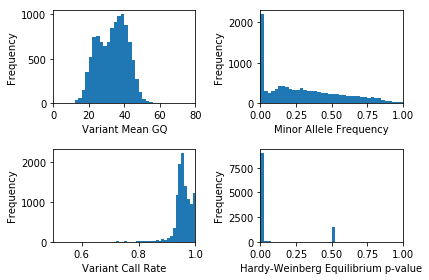
These statistics actually look pretty good: we don’t need to filter this dataset. Most datasets require thoughtful quality control, though. The filter_variants_expr method can help!
Let’s do a GWAS!¶
First, we need to restrict to variants that are :
- common (we’ll use a cutoff of 1%)
- uncorrelated (not in linkage disequilibrium)
Both of these are easy in Hail.
In [43]:
common_vds = (vds
.filter_variants_expr('va.qc.AF > 0.01')
.ld_prune(memory_per_core=256, num_cores=4))
2018-10-18 01:26:50 Hail: INFO: Running LD prune with nSamples=843, nVariants=9085, nPartitions=4, and maxQueueSize=257123.
2018-10-18 01:26:50 Hail: INFO: LD prune step 1 of 3: nVariantsKept=8478, nPartitions=4, time=351.375ms
2018-10-18 01:26:51 Hail: INFO: LD prune step 2 of 3: nVariantsKept=8478, nPartitions=12, time=1.184s
2018-10-18 01:26:52 Hail: INFO: Coerced sorted dataset
2018-10-18 01:26:52 Hail: INFO: LD prune step 3 of 3: nVariantsKept=8478, time=481.478ms
In [44]:
common_vds.count()
Out[44]:
(843L, 8555L)
These filters removed about 15% of sites (we started with a bit over 10,000). This is NOT representative of most sequencing datasets! We have already downsampled the full thousand genomes dataset to include more common variants than we’d expect by chance.
In Hail, the association tests accept sample annotations for the sample phenotype and covariates. Since we’ve already got our phenotype of interest (caffeine consumption) in the dataset, we are good to go:
In [45]:
gwas = common_vds.linreg('sa.CaffeineConsumption')
pprint(gwas.variant_schema)
2018-10-18 01:26:52 Hail: INFO: Running linear regression on 843 samples with 1 covariate including intercept...
Struct{
rsid: String,
qual: Double,
filters: Set[String],
pass: Boolean,
info: Struct{
AC: Array[Int],
AF: Array[Double],
AN: Int,
BaseQRankSum: Double,
ClippingRankSum: Double,
DP: Int,
DS: Boolean,
FS: Double,
HaplotypeScore: Double,
InbreedingCoeff: Double,
MLEAC: Array[Int],
MLEAF: Array[Double],
MQ: Double,
MQ0: Int,
MQRankSum: Double,
QD: Double,
ReadPosRankSum: Double,
set: String
},
qc: Struct{
callRate: Double,
AC: Int,
AF: Double,
nCalled: Int,
nNotCalled: Int,
nHomRef: Int,
nHet: Int,
nHomVar: Int,
dpMean: Double,
dpStDev: Double,
gqMean: Double,
gqStDev: Double,
nNonRef: Int,
rHeterozygosity: Double,
rHetHomVar: Double,
rExpectedHetFrequency: Double,
pHWE: Double
},
linreg: Struct{
beta: Double,
se: Double,
tstat: Double,
pval: Double
}
}
Looking at the bottom of the above printout, you can see the linear regression adds new variant annotations for the beta, standard error, t-statistic, and p-value.
In [46]:
def qqplot(pvals, xMax, yMax):
spvals = sorted(filter(lambda x: x and not(isnan(x)), pvals))
exp = [-log(float(i) / len(spvals), 10) for i in np.arange(1, len(spvals) + 1, 1)]
obs = [-log(p, 10) for p in spvals]
plt.clf()
plt.scatter(exp, obs)
plt.plot(np.arange(0, max(xMax, yMax)), c="red")
plt.xlabel("Expected p-value (-log10 scale)")
plt.ylabel("Observed p-value (-log10 scale)")
plt.xlim(0, xMax)
plt.ylim(0, yMax)
plt.show()
Python makes it easy to make a Q-Q (quantile-quantile) plot.
In [47]:
qqplot(gwas.query_variants('variants.map(v => va.linreg.pval).collect()'),
5, 6)
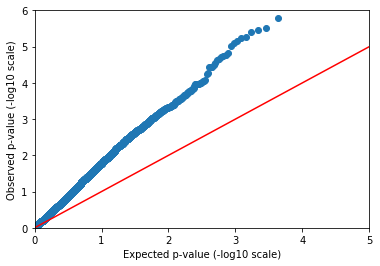
Confounded!¶
The observed p-values drift away from the expectation immediately. Either every SNP in our dataset is causally linked to caffeine consumption (unlikely), or there’s a confounder.
We didn’t tell you, but sample ancestry was actually used to simulate this phenotype. This leads to a stratified distribution of the phenotype. The solution is to include ancestry as a covariate in our regression.
The linreg method can also take sample annotations to use as covariates. We already annotated our samples with reported ancestry, but it is good to be skeptical of these labels due to human error. Genomes don’t have that problem! Instead of using reported ancestry, we will use genetic ancestry by including computed principal components in our model.
The pca method produces sample PCs in sample annotations, and can also produce variant loadings and global eigenvalues when asked.
In [48]:
pca = common_vds.pca('sa.pca', k=5, eigenvalues='global.eigen')
2018-10-18 01:26:55 Hail: INFO: Running PCA with 5 components...
In [49]:
pprint(pca.globals)
{u'eigen': {u'PC1': 56.34707905481798,
u'PC2': 37.8109003010398,
u'PC3': 16.91974301822238,
u'PC4': 2.707349935634387,
u'PC5': 2.0851252187821174}}
In [50]:
pprint(pca.sample_schema)
Struct{
Population: String,
SuperPopulation: String,
isFemale: Boolean,
PurpleHair: Boolean,
CaffeineConsumption: Int,
qc: Struct{
callRate: Double,
nCalled: Int,
nNotCalled: Int,
nHomRef: Int,
nHet: Int,
nHomVar: Int,
nSNP: Int,
nInsertion: Int,
nDeletion: Int,
nSingleton: Int,
nTransition: Int,
nTransversion: Int,
dpMean: Double,
dpStDev: Double,
gqMean: Double,
gqStDev: Double,
nNonRef: Int,
rTiTv: Double,
rHetHomVar: Double,
rInsertionDeletion: Double
},
pca: Struct{
PC1: Double,
PC2: Double,
PC3: Double,
PC4: Double,
PC5: Double
}
}
Now that we’ve got principal components per sample, we may as well plot them! Human history exerts a strong effect in genetic datasets. Even with a 50MB sequencing dataset, we can recover the major human populations.
In [51]:
pca_table = pca.samples_table().to_pandas()
colors = {'AFR': 'green', 'AMR': 'red', 'EAS': 'black', 'EUR': 'blue', 'SAS': 'cyan'}
plt.scatter(pca_table["sa.pca.PC1"], pca_table["sa.pca.PC2"],
c = pca_table["sa.SuperPopulation"].map(colors),
alpha = .5)
plt.xlim(-0.6, 0.6)
plt.xlabel("PC1")
plt.ylabel("PC2")
legend_entries = [mpatches.Patch(color=c, label=pheno) for pheno, c in colors.items()]
plt.legend(handles=legend_entries, loc=2)
plt.show()
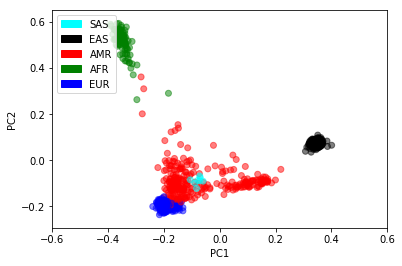
Now we can rerun our linear regression, controlling for the first few principal components and sample sex.
In [52]:
pvals = (common_vds
.annotate_samples_table(pca.samples_table(), expr='sa.pca = table.pca')
.linreg('sa.CaffeineConsumption', covariates=['sa.pca.PC1', 'sa.pca.PC2', 'sa.pca.PC3', 'sa.isFemale'])
.query_variants('variants.map(v => va.linreg.pval).collect()'))
2018-10-18 01:27:07 Hail: INFO: Running linear regression on 843 samples with 5 covariates including intercept...
In [53]:
qqplot(pvals, 5, 6)
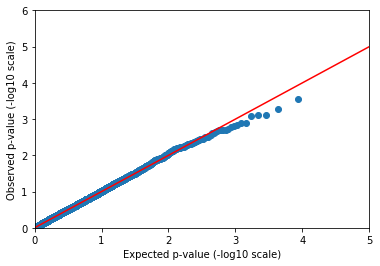
In [54]:
pvals = (common_vds
.annotate_samples_table(pca.samples_table(), expr='sa.pca = table.pca')
.linreg('sa.CaffeineConsumption',
covariates=['sa.pca.PC1', 'sa.pca.PC2', 'sa.pca.PC3', 'sa.isFemale'],
use_dosages=True)
.query_variants('variants.map(v => va.linreg.pval).collect()'))
2018-10-18 01:27:08 Hail: INFO: Running linear regression on 843 samples with 5 covariates including intercept...
In [55]:
qqplot(pvals, 5, 6)
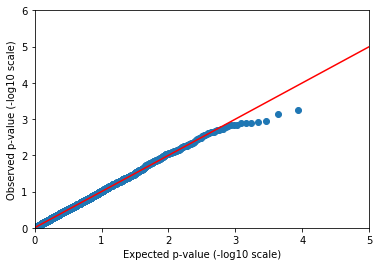
That’s more like it! We may not be publishing ten new coffee-drinking loci in Nature, but we shouldn’t expect to find anything but the strongest signals from a dataset of 1000 individuals anyway.
Rare variant analysis¶
Hail doesn’t yet have rare variant kernel-based methods, but we have linear and logistic burden tests.
We won’t be showing those here, though. Instead, we’ll demonstrate how one can use the expression language to group and count by any arbitrary properties in variant or sample annotations.
In [56]:
kt = (vds.genotypes_table()
.aggregate_by_key(key_expr=['pop = sa.SuperPopulation', 'chromosome = v.contig'],
agg_expr=['n_het = g.filter(g => g.isHet()).count()']))
In [57]:
kt.to_dataframe().show()
+---+----------+-----+
|pop|chromosome|n_het|
+---+----------+-----+
|EUR| 14|16380|
|SAS| 17| 511|
|EUR| 5|30717|
|AFR| 7|11889|
|EAS| 9|23951|
|AFR| 21| 3529|
|EAS| X| 7403|
|EAS| 1|49375|
|EUR| 19|13483|
|AMR| 15|18935|
|AMR| 7|31527|
|EUR| 13|17321|
|EUR| 12|26134|
|EUR| 15|15807|
|EUR| 6|33910|
|EAS| 20|17466|
|SAS| 11| 901|
|AFR| 3|15829|
|EAS| 2|45384|
|AMR| 18|18982|
+---+----------+-----+
only showing top 20 rows
What if we want to group by minor allele frequency bin and hair color, and calculate the mean GQ?
In [58]:
kt2 = (vds.genotypes_table()
.aggregate_by_key(key_expr=['''maf_bin = if (va.qc.AF < 0.01) "< 1%"
else if (va.qc.AF < 0.05) "1%-5%"
else "> 5%" ''',
'purple_hair = sa.PurpleHair'],
agg_expr=['mean_gq = g.map(g => g.gq).stats().mean',
'mean_dp = g.map(g => g.dp).stats().mean']))
In [59]:
kt2.to_dataframe().show()
+-------+-----------+------------------+-----------------+
|maf_bin|purple_hair| mean_gq| mean_dp|
+-------+-----------+------------------+-----------------+
| > 5%| true| 36.09305651197578|7.407450459057423|
| < 1%| true| 22.68197887434976|7.374254453728496|
| < 1%| false|22.986128698357074|7.492131714314245|
| > 5%| false|36.341259980753755|7.533399982371768|
| 1%-5%| true|24.093123033233528|7.269552536649012|
| 1%-5%| false| 24.3519587208908|7.405582424428774|
+-------+-----------+------------------+-----------------+
We’ve shown that it’s easy to aggregate by a couple of arbitrary statistics. This specific examples may not provide especially useful pieces of information, but this same pattern can be used to detect effects of rare variation:
- Count the number of heterozygous genotypes per gene by functional category (synonymous, missense, or loss-of-function) to estimate per-gene functional constraint
- Count the number of singleton loss-of-function mutations per gene in cases and controls to detect genes involved in disease
Eplilogue¶
Congrats! If you’ve made it this far, you’re perfectly primed to read the Overview, look through the Hail objects representing many core concepts in genetics, and check out the many Hail functions defined in the Python API. If you use Hail for your own science, we’d love to hear from you on Gitter chat or the discussion forum.
There’s also a lot of functionality inside Hail that we didn’t get to in this broad overview. Things like:
- Flexible import and export to a variety of data and annotation formats (VCF, BGEN, PLINK, JSON, TSV, …)
- Simulation
- Burden tests
- Kinship and pruning (IBD, GRM, RRM)
- Family-based tests and utilities
- Distributed file system utilities
- Interoperability with Python and Spark machine learning libraries
- More!
For reference, here’s the full workflow to all tutorial endpoints combined into one cell. It may take a minute! It’s doing a lot of work.
In [60]:
table = hc.import_table('data/1kg_annotations.txt', impute=True).key_by('Sample')
common_vds = (hc.read('data/1kg.vds')
.annotate_samples_table(table, root='sa')
.sample_qc()
.filter_samples_expr('sa.qc.dpMean >= 4 && sa.qc.callRate >= 0.97')
.filter_genotypes('''let ab = g.ad[1] / g.ad.sum() in
((g.isHomRef && ab <= 0.1) ||
(g.isHet && ab >= 0.25 && ab <= 0.75) ||
(g.isHomVar && ab >= 0.9))''')
.variant_qc()
.filter_variants_expr('va.qc.AF > 0.01')
.ld_prune(memory_per_core=512, num_cores=4))
pca = common_vds.pca('sa.pca', k=5, eigenvalues='global.eigen')
pvals = (common_vds
.annotate_samples_table(pca.samples_table(), expr='sa.pca = table.pca')
.linreg('sa.CaffeineConsumption', covariates=['sa.pca.PC1', 'sa.pca.PC2', 'sa.pca.PC3', 'sa.isFemale'])
.query_variants('variants.map(v => va.linreg.pval).collect()'))
2018-10-18 01:27:14 Hail: INFO: Reading table to impute column types
2018-10-18 01:27:14 Hail: INFO: Finished type imputation
Loading column `Sample' as type String (imputed)
Loading column `Population' as type String (imputed)
Loading column `SuperPopulation' as type String (imputed)
Loading column `isFemale' as type Boolean (imputed)
Loading column `PurpleHair' as type Boolean (imputed)
Loading column `CaffeineConsumption' as type Int (imputed)
2018-10-18 01:27:21 Hail: INFO: Running LD prune with nSamples=843, nVariants=9085, nPartitions=4, and maxQueueSize=514245.
2018-10-18 01:27:27 Hail: INFO: LD prune step 1 of 3: nVariantsKept=8478, nPartitions=4, time=6.067s
2018-10-18 01:27:28 Hail: INFO: LD prune step 2 of 3: nVariantsKept=8478, nPartitions=12, time=655.317ms
2018-10-18 01:27:28 Hail: INFO: Coerced sorted dataset
2018-10-18 01:27:28 Hail: INFO: LD prune step 3 of 3: nVariantsKept=8478, time=255.964ms
2018-10-18 01:27:28 Hail: INFO: Running PCA with 5 components...
2018-10-18 01:27:49 Hail: INFO: Running linear regression on 843 samples with 5 covariates including intercept...